爬虫开发内容
一、爬虫为什么偏爱Python?
1. 语法简洁,开发效率高
Python代码可读性强、语法简洁,同样的爬虫功能,用Python实现可能只需几十行代码,而用Java、C++可能需要上百行,适合快速开发和迭代。
2. 强大的爬虫库生态
有大量成熟的第三方库,无需重复造轮子:
◦requests:简单高效的HTTP请求库,处理GET/POST等请求非常方便。
◦BeautifulSoup/lxml:解析HTML/XML文档,快速提取数据(如标签、属性、文本)。
◦Scrapy:专业的爬虫框架,内置异步处理、爬虫中间件、数据管道等,适合大规模爬虫项目。
◦ Selenium/Playwright:模拟浏览器行为,处理JavaScript动态加载的页面(如登录、滑动验证)。
3. 灵活处理数据
爬虫获取数据后,可直接用Python的pandas(数据处理)、json(解析JSON)等库清洗、存储,无缝衔接后续流程。
常用的爬虫软件大致分为万能通用型、浏览器自动化型、无代码交互式这三种。
万能通用型的爬虫工具:Scrapy、requests;
浏览器自动化型的爬虫工具:selenium、puppeteer、playwright,但都需要有代码能力才能实现数据采集;
无代码交互式爬虫工具:八爪鱼、web scrapy、Instant Data Scraper,你只需要学会固定的数据采集配置规则,简单的拖拉拽就可以实现数据的抓取,比较类似于Excel、PS等可视化软件。
Python 爬虫,专治各种疑难杂症,特别是动态网页数据抓取!现在好多网站都用 JavaScript 动态加载内容,传统的爬虫方法不好使了,所以得拿出点真本事。咱们这次就聊聊 Scrapy 、Selenium,还有怎么绕过反爬虫机制,走起!
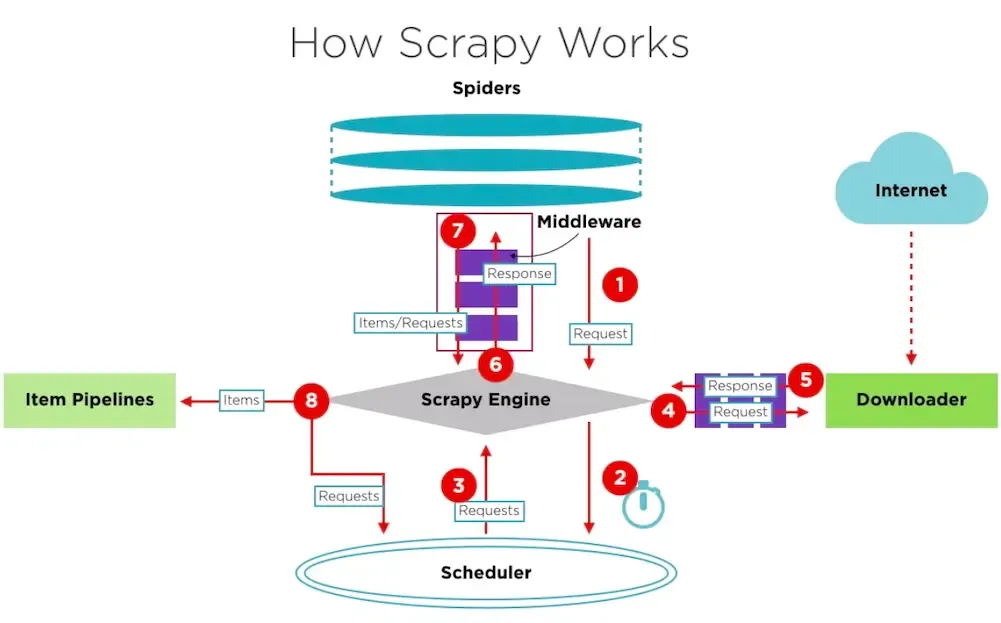
Scrapy 框架:爬虫界的扛把子
Scrapy 这玩意儿,那可是爬虫界的扛把子,强大得很!它内置了一堆好用的功能,像请求调度、数据提取、管道处理等等,都能轻松搞定。写爬虫就像搭积木一样,简单又高效。
1 2 3 4 5 6 7 8 9 10
import scrapy
classMySpider(scrapy.Spider):
name =“myspider”
start_urls =[“http://www.example.com”]
def parse(self, response):
# 这里用XPath提取数据,贼方便
for title in response.xpath(“//h2/text()”).getall():
yield{“title”:title}这段代码,先定义一个爬虫类,指定起始 URL,然后在parse方法里用 XPath 提取标题。XPath 这玩意儿,就像一把手术刀,精准定位网页元素,贼好用!
Selenium:模拟浏览器行为的高手
有些网站,数据是 JavaScript 动态加载的,Scrapy 直接抓取拿不到。这时候就得请出 Selenium 了。它能模拟浏览器行为,执行 JavaScript 代码,拿到动态加载的数据。